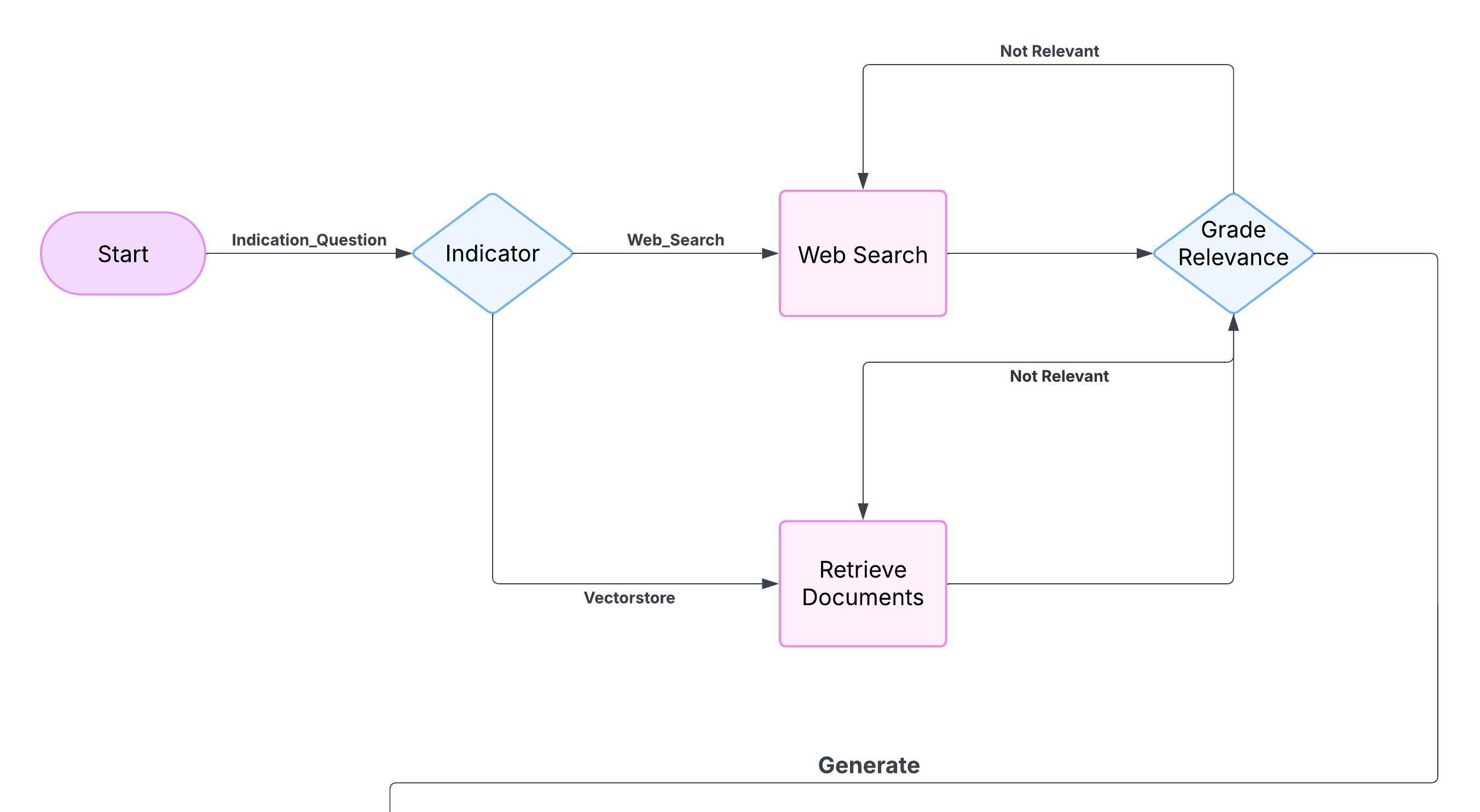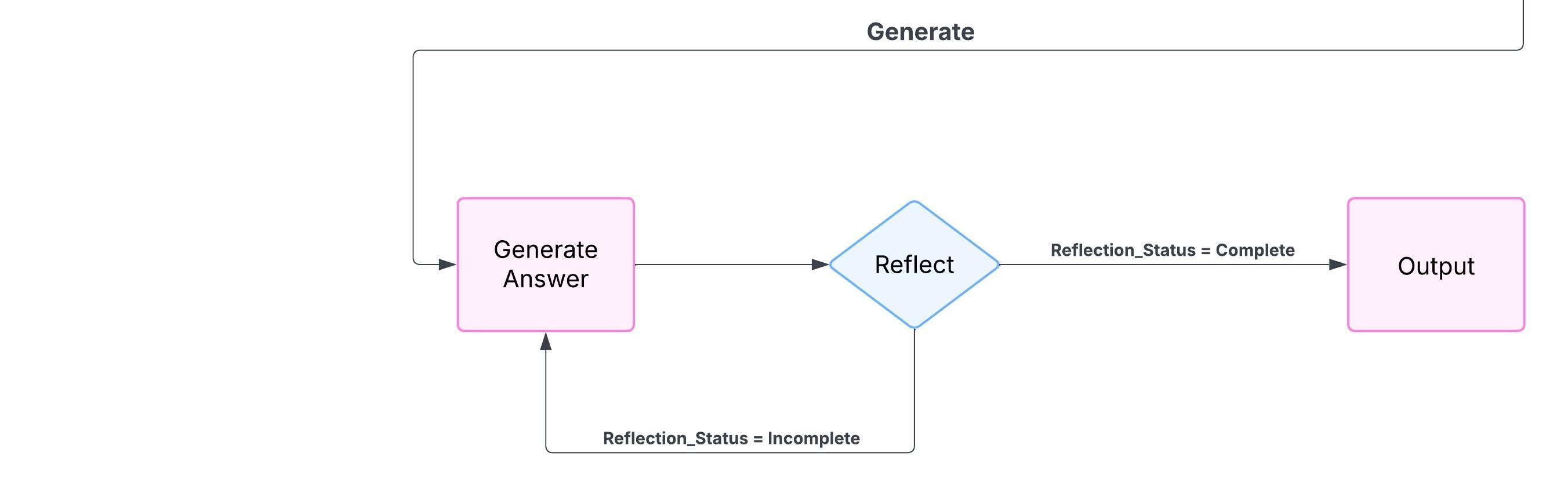
The Self-Correcting RAG System is a locally deployed assistant built using Python, Ollama (with llama3.1), and ChromaDB, designed to deliver factually grounded answers from regulatory PDFs like the Auckland Unitary Plan. It routes questions through a custom state graph that selects between local document retrieval and Tavily-powered web search. Responses are generated via a local LLM, then validated through relevance grading, hallucination detection, and reflection loops—regenerating when necessary. This fully automated system ensures accuracy and completeness, continuously improving responses with each interaction without manual oversight.
Key Capabilities
- Autonomous Decision-Making – Dynamically chooses vector retrieval or web search based on zoning and regulatory relevance.
- Self-Correcting Answer Generation – Uses reflection and hallucination grading to refine responses without user input.
- StateGraph-Controlled Workflow – Executes modular nodes for retrieval, generation, grading, reflection, and routing.
- Chroma-Backed Relevance Retrieval – Retrieves and filters document chunks from ChromaDB using Ollama embeddings.
- Iterative Output Validation – Detects missing info or hallucinations and triggers regeneration from updated context.
- Fully Local & Privacy-First – Runs entirely offline with local LLMs and PDF data, preserving user privacy and control.